
Знакомство
Мир искусственного интеллекта стремительно развивался, особенно с появлением векторных баз данных, таких как Pinecone. Эти базы данных обеспечивают эффективное, масштабируемое хранение и выполнение запросов к многомерным векторным встраиваниям, которые играют ключевую роль в различных приложениях искусственного интеллекта, таких как обработка естественного языка (NLP), рекомендательные системы и семантический поиск. В этой статье мы рассмотрим, как преобразовать PDF-файлы в векторные встраивания и сохранить их в Pinecone с помощью LangChain, надежного фреймворка для создания приложений на основе LLM.
К концу этого руководства у вас будет четкое представление о том, как конвертировать текстовые данные из PDF-файлов в векторизованный формат, хранить их в Pinecone и эффективно извлекать для дальнейшего анализа. Мы пройдем через каждый этап, от создания учетной записи до встраивания хранилища и извлечения, используя практические примеры кода Python, структурированные с использованием чистых принципов кода, таких как построение классов и реализация модульных функций. Этот рабочий процесс подходит для всех, кто хочет работать с задачами хранения и извлечения документов в приложениях NLP.
Что такое Pinecone?
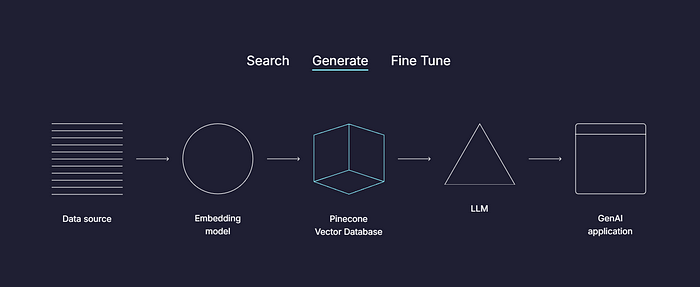
Pinecone — это полностью управляемая векторная база данных, предназначенная для крупномасштабных приложений машинного обучения в режиме реального времени. В отличие от традиционных баз данных, Pinecone оптимизирован для обработки многомерных векторных представлений данных, что делает его идеальным для приложений в области искусственного интеллекта, особенно тех, которые включают встраивание текста, изображений и многого другого.
По своей сути, Pinecone предлагает быстрое, масштабируемое решение для хранения и извлечения векторных встраиваний, которые представляют собой числовые представления данных, таких как слова или документы. Эти векторы можно использовать для таких задач, как поиск сходства, кластеризация и рекомендации, так как они фиксируют семантическую сущность входных данных. Pinecone предоставляет различные API для упрощения процесса интеграции, что упрощает разработчикам использование платформы на разных языках программирования.
Для практиков искусственного интеллекта масштабируемость Pinecone и низкая задержка делают его ценным инструментом для управления встраиваниями, созданными такими моделями, как GPT от OpenAI, BERT от Google, или пользовательскими встраиваниями, созданными на основе ваших данных. Встроенная поддержка векторного извлечения гарантирует, что производительность останется стабильной даже при увеличении размера набора данных.
Создание учетной записи Pinecone и ключа API
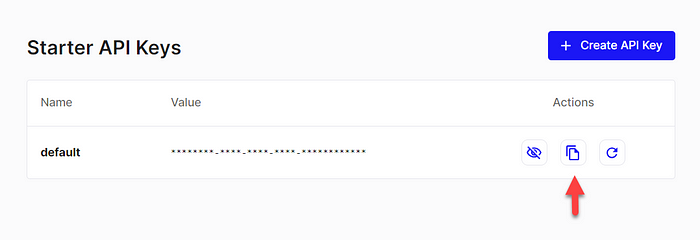
Прежде чем мы погрузимся в создание нашего векторного магазина, вам необходимо создать учетную запись Pinecone и получить ключ API для доступа к сервису.
Шаги по созданию учетной записи Pinecone:
- Посетите веб-сайт Pinecone и зарегистрируйте учетную запись.
- После регистрации перейдите в раздел «Ключи API» на панели управления.
- Нажмите «Создать ключ API», дайте ему имя и обязательно скопируйте ключ для последующего использования.
Этот ключ API будет необходим для взаимодействия с API Pinecone для всех взаимодействий, таких как создание индекса, вставка векторов и запрос сохраненных данных.
Теперь, когда у вас под рукой есть ключ API Pinecone, вы готовы интегрировать его со своими скриптами Python и начать хранить векторы из PDF-документов.
Преобразование PDF-файлов в текст
Первым шагом в создании векторного магазина из PDF-файлов является преобразование PDF-содержимого в текст. Это можно сделать с помощью таких библиотек, как PyMuPDF или PDFMiner. После того, как мы извлечем текст, мы можем перейти к его встраиванию с помощью языковой модели.
Вот пример того, как извлечь текст из PDF с помощью PyMuPDF:
import fitz # PyMuPDF
класс PDFПоадер:
def __init__(self, pdf_path):
self.pdf_path = pdf_path
def extract_text(self):
doc = fitz.open(self.pdf_путь)
текст = ""
Для страницы в документе:
текст += page.get_text()
Возврат текста
если __name__ =='__main__':
loader = PDFLoader('example.pdf')
текст = loader.extract_text()
print(текст)
В этом фрагменте кода мы создаем PDFLoader класс, который извлекает текст с каждой страницы PDF-файла и объединяет его в одну строку. В дальнейшем этот текст можно использовать для создания вложений.
Встраиваемая модель
После того, как вы получили текст из PDF-файла, следующим шагом будет преобразование его в векторные вложения. Для этой цели доступно несколько моделей, в том числе модели OpenAI, универсальный кодировщик предложений Google и модели Hugging Face. Для этого примера мы будем использовать модель OpenAI text-embedding-ada-002 .
Чтобы использовать модель OpenAI, убедитесь, что у вас есть ключ API и установлен пакет OpenAI Python.
Из load_dotenv импорта dotenv
Импорт ОС
Импорт тиктокена
Импорт OpenAI
load_dotenv() # Загрузка переменных окружения из файла .env
класс EmbeddingGenerator:
def __init__(self):
# Загрузка ключа API из переменных окружения
openai_api_key = os.getenv("OPENAI_API_KEY")
Если нет openai_api_key:
raise ValueError("OPENAI_API_KEY переменная среды не установлена")
def chunk_text_by_tokens(self, text, chunk_size, encoding_name="cl100k_base"):
"""
Разбивает текст на части в зависимости от количества токенов.
"""
кодировка = tiktoken.get_encoding(encoding_name)
токены = encoding.encode(текст)
return [encoding.decode(tokens[i:i + chunk_size]) для i in range(0, len(tokens), chunk_size)]
def generate_embeddings(self, chunks):
"""
Создает вложения для каждого блока и возвращает список вложений.
"""
вложения = []
Для чанка в чанках:
response = openai.embeddings.create(
input=chunk,
model="text-embedding-ada-002"
)
embeddings.append(response.data[0].embedding)
Возвратные вложения
def process_text(self, text, chunk_size=1000):
"""
Разбивает текст на части и генерирует вложения.
"""
chunks = self.chunk_text_by_tokens(текст, chunk_size)
вложения = self.generate_embeddings(чанки)
Возвращаемые чанки, вложения
если __name__ =='__main__':
generator = EmbeddingGenerator()
Чанки, вложения = generator.process_text(текст, chunk_size=800)
OpenAI text-embedding-ada-002 высоко оптимизирован для создания плотных вложений текста, подходит для большинства случаев использования. Другие модели, такие как Universal Sentence Encoder от Google или модели от Hugging Face, также можно использовать в зависимости от требований вашего проекта.
Сохранение векторов в Pinecone
После того, как вложения сгенерированы, нам нужно сохранить их в Pinecone. Pinecone позволяет создать индекс для хранения этих вложений для быстрого доступа.
Импорт сосновых шишек
load_dotenv() # Загрузка переменных окружения из файла .env
класс PineconeStore:
def __init__(self, environment="us-east-1"):
# Загрузка ключа API из переменных окружения
pinecone_api_key = os.getenv("PINECONE_API_KEY")
Если нет pinecone_api_key:
raise ValueError("PINECONE_API_KEY переменная среды не установлена")
# Создание экземпляра Pinecone
self.pc = Сосновая шишка(api_key=pinecone_api_key)
# Определите имя индекса
self.index_name = "pdf-вектор-магазин"
# Проверьте, существует ли индекс, если нет его создайте
если self.index_name нет в self.pc.list_indexes().names():
self.pc.create_index(
name=self.index_name,
размер=1536,
metric='косинус',
spec=ServerlessSpec(cloud='aws', region='us-east-1')
)
def save_vectors(self, векторы, метаданные, фрагменты):
# Получить индекс
index = self.pc.index(self.index_name)
# Перебирайте встраиваемые элементы и сохраняйте каждое из них с уникальными метаданными
Для i, вектор в Enumerate(векторы):
vector_id = f"{metadata['id']}_chunk_{i}" # Уникальный идентификатор для каждого чанка
chunk_metadata = {
"id": vector_id,
"источник": метаданные["источник"],
"кусок": я,
"text": chunks[i] # Добавьте текст фрагмента сюда
}
# Поднимите каждый вектор с соответствующими ему метаданными
index.upsert(векторы=[(vector_id, вектор, chunk_metadata)])
если __name__ =='__main__':
vector_store = PineconeStore()
vector_store.save_vector(встраивание, {"id": "doc_1", "источник": "example.pdf"}, фрагменты)
Этот код определяет PineconeStore класс для управления хранилищем векторов Pinecone. Он инициализирует подключение к Pinecone с помощью ключа API, загруженного из переменных среды, и создает векторный индекс, если он еще не существует.
Метод save_vectors позволяет сохранять векторы в индекс Pinecone, связывая каждый вектор с уникальными метаданными, включая идентификатор, источник, индекс блока и текст блока. Скрипт демонстрирует, как создать экземпляр класса и использовать его для сохранения векторов с метаданными в индекс Pinecone.
Доступ к векторной базе данных с помощью API Pinecone
После сохранения векторов их извлечение для дальнейшей обработки не вызывает затруднений с помощью API Pinecone. Вы можете искать векторы, похожие на вектор запроса, или извлекать определенные векторы по идентификатору.
Из load_dotenv импорта dotenv
Импорт ОС
из сосновой шишки импорт Сосновая шишка
из langchain_pinecone импорта PineconeVectorStore
из langchain_openai импорта OpenAIЭмбеддинги, OpenAI
из langchain.chains импортирует RetrievalQA
класс PineconeRetriever:
def __init__(self, pinecone_api_key, openai_api_key):
load_dotenv() # Загрузка переменных окружения из файла .env
# Инициализация подключения к сосновым шишкам
self.pc = Сосновая шишка(api_key=pinecone_api_key)
self.index_name = "pdf-вектор-магазин"
self.index = self.pc.index(self.index_name)
# Инициализация модели OpenAI и встраивания
self.embedding_model = OpenAIEmbeddings(openai_api_key=openai_api_key)
self.llm = OpenAI(температура=0, api_key=openai_api_key)
# Создание векторного магазина Pinecone
self.vector_store = PineconeVectorStore(index=self.index, embedding=self.embedding_model, text_key="text")
self.retriever = self.vector_store.as_retriever()
# Создание цепочки RetrievalQA
self.qa_chain = RetrievalQA.from_chain_type(llm=self.llm, chain_type="stuff", retriever=self.retriever)
def query(self, query_text):
# Выполнение QA цепочки с входным запросом
response = self.qa_chain.invoke({"query": query_text})
вернуть ответ['результат']
если __name__ =='__main__':
# Замените на свои актуальные ключи API
pinecone_api_key = os.getenv("PINECONE_API_KEY")
openai_api_key = os.getenv("OPENAI_API_KEY")
retriever = PineconeRetriever(pinecone_api_key=pinecone_api_key, openai_api_key=openai_api_key)
result = retriever.query("ВАШ ЗАПРОС ЗДЕСЬ")
print(результат)
Этот код определяет PineconeRetriever класс, который интегрируется с сервисами Pinecone и OpenAI для выполнения текстовых запросов. После инициализации он устанавливает соединения с Pinecone и OpenAI, создает векторное хранилище с помощью Pinecone и устанавливает цепочку RetrievalQA с языковой моделью OpenAI.
Этот query метод позволяет пользователям отправлять текст запроса, который обрабатывается цепочкой контроля качества для получения соответствующей информации. Затем скрипт демонстрирует, как создать экземпляр класса с ключами API и использовать его для выполнения запроса, выводя результат.
Заключение
Создание векторного хранилища из PDF-документов с помощью Pinecone и LangChain — это эффективный способ управления и извлечения семантической информации из больших текстовых данных. Преобразуя PDF-файлы во встраиваемые файлы, сохраняя их в Pinecone и используя LangChain для управления рабочим процессом, вы можете оптимизировать процесс создания интеллектуальных поисковых систем или рекомендательных механизмов.
Эффективное векторное хранилище Pinecone в сочетании с гибкостью LangChain делает его отличным выбором для масштабируемых приложений искусственного интеллекта для поиска документов и управления знаниями.
Подключение и совместная работа
Если вы нашли этот проект интересным и хотели бы узнать больше о машинном обучении, обработке естественного языка или любых других связанных темах, не стесняйтесь связаться со мной на LinkedIn. Я всегда рад общаться с коллегами-энтузиастами и профессионалами в этой области.
Чтобы узнать больше о моих проектах и коде, посетите мой GitHub. Вы найдете множество проектов, демонстрирующих мою работу в области науки о данных, машинного обучения и не только. Не стесняйтесь обращаться к нам, если у вас есть какие-либо вопросы или идеи для сотрудничества.
